
Have you heard of the “duck syndrome”? The concept describes a duck appearing to glide effortlessly across a stream but paddling furiously under the water’s surface and is typically used to describe someone that presents as relaxed but is working tirelessly to maintain that appearance.
Kafka Streams gives new life to this idiom — it presents an API surface area that appears simple, but the underlying technology works exceptionally hard to make that a reality.
As a co-founder of a company that focuses on solving Kafka Streams’ operational pains, I frequently discuss the challenges that come from the “furious underwater paddling”. More than once I’ve been confronted with the idea that perhaps it would be easier to build an application without a stream processing framework at all, relying on only the KafkaConsumer primitive.
With this post, I pull back the curtains on what goes into building a reliable event-driven application by shining a light on the internals of Kafka Streams and why we think it’s a foundational technology for writing such apps — so foundational that we’re betting our company on it.
Put on your snorkels, let’s take a look underneath the water.
What is a “Stream Processor”?
A stream processor continuously ingests and processes event streams in real-time, applying operations such as filtering, aggregation, joins and transformations. The event-by-event processing makes it an ideal programming model for event-driven applications as well as situations where low-latency reactions to individual events are critical.
There are various state-of-the-art stream processors such as Kafka Streams that share similar characteristics (for a comparison of why you’d want to choose one or the other, see our whitepaper on the subject). Focusing on Kafka Streams, the framework comes out of the box with:
| Functional Attributes | Non-Functional Attributes |
|---|---|
| F1. A programming model that supports handling one event at a time, in a well-defined and deterministic ordering. | N1. An emphasis on sub-second latency for processing events. |
| F2. A fully-featured DSL that can filter, transform, window, aggregate and join event streams. | N2. Fault tolerance mechanisms that support high availability. |
| F3. Transactional processing to ensure exactly-once semantics. | N3. The ability to scale horizontally and add computational resources to address performance bottlenecks. |
| F4. Packaged with a suite of development tooling such as: a testing harness, state inspection and observability. | N4. Managing the consistency of storage sub-systems. |
| N5. Robust error handling mechanisms to ensure errors at any layer of processing are routed appropriately. |
These table items forms the basis of a stream processing technology. If you are not yet dissuaded from building them on your own, then read on — we’re about to get technical and explain the effort put into Kafka Streams to provide this functionality.
Step 1: Build the Runtime
The runtime covers the first two functional attributes (F1, F2) in the table above.
This core is implemented as a poll/process/commit loop. If you were writing this loop from scratch, you would need to answer the following questions:
What operators do I need to implement?
Consequence of getting it wrong: Implementing operators incorrectly will, obviously, produce incorrect results!
So now that we’ve determined which event to process, Kafka Streams needs to make sure that the processing code is executed correctly. At a high level, a stream processing application needs to read data, read/write some state associated with that data, and then write back results. However, it’s quite challenging to do this correctly (F2).
For example, you might be taking the sum of values with a given key. You need to make sure that all the values with that key are included in that count exactly once. You might then want to enrich another topic’s data with those counts, so you need to make the counts accessible to the consumer of that topic.
In Kafka Streams, we’ve observed that most applications are composed of a series of common computations like projections, aggregates, and joins, etc so we solve this by providing you with a DSL that compiles down to a topology of these operations, and then tackle these problems for each node of the topology as described in the table below.
Here’s a non-exhaustive list of processors that are available out-of-the-box with Kafka Streams and a short description of the challenges faced with implementing them properly:
| Feature | Description |
|---|---|
| Stateless Stream Filters & Value-Transforms | These are the simplest of the processors and there are only some minor challenges (such as proper null handling, which is generally done by the framework at large). |
| Stateful Transforms | Any operation on the result of a stateful computation (see this paper on the stream-table duality for more details) involve ensuring the underlying materialized state is in sync. We’ll describe this in more detail when talking about managing storage sub-systems (N4). |
| Aggregations | Aggregations are when the DSL begins to increase in complexity. An aggregate needs to define what it aggregates on (the key), a potential window to aggregate within and the aggregation logic. Kafka Streams handles all this for a myriad of different types of aggregations (see this blog as an overview) and ensures correct and deterministic results. |
| Joins | Just as, if not more, complicated than correctly implementing aggregations, joins are the focus area of much academic research. Kafka Streams implements many different types of joins, each of which requires its own distinct and complex implementation (up to the infamous Foreign-Key joins, which you can read about in full gory detail here). |
Getting the semantics correct for these operations requires years of dedication and bug-bashing. You can see just some examples of discussions on Kafka Streams’ implementation with these tickets, which have since been resolved or determined to be correct semantics: KAFKA-10847, KAFKA-7595 and KAFKA-15417.1
This table is just the current state of the DSL! There are open suggestions (1, 2, …) for expanding the surface area to ensure that users have access to correctly implemented primitives for writing stream processing applications.
How can I ensure correct results?
Consequences of getting it wrong: corrupt, incomplete, duplicate or missing results
There’s two mechanisms that go into correct results:
- Transaction coordination for Exactly Once Semantics (we wrote an entire blog on this if you want more details)
- Consistent state management (read our overview of state in Kafka Streams for more details about this)
Each of these on their own was meaty enough to warrant a full blog post, but the interplay between the two complicates things even further: ensuring that the state is always consistent with what has been transactionally processed is a challenge (N4).
To handle this, each state store in Kafka Streams is associated with a changelog topic for fault tolerance and transactional semantics. Whenever the state store is updated the changes are also produced to the changelog using the Kafka transaction protocol, which can be replayed during recovery.
In the case of Responsive and remote storage, the changelog topic is effectively a Write-Ahead Log — if the application crashes after transactionally committing the result of processing to Kafka but before successfully flushing to the remote store, that delta can be recovered by replaying only the tail of the changelog topic.
Which topic-partition should I process?
Consequence of getting it wrong: (1) event streams are processed indeterministically, (2) join results may be incorrect and (3) performance may suffer.
Let’s punt the question of how topic-partitions are assigned to an instance of Kafka Streams for now (we’ll discuss that later) and assume that a certain set of partitions have already been allocated. Since the API processes one event at a time, the processor must determine which event from which partition to pipe into the processing topology first.
Kafka Streams implements this thoughtfully and carefully. While the poll phase always runs (it requests records from the broker for all partitions), the records returned are initially buffered. Even if there are buffered to-be-processed records, they may not be immediately forwarded to the processor if the buffer does not contain data for all input partitions (see KIP-353 and KIP-695 to understand the full nuance that went into cementing the semantics). Without this buffering it is also possible for join semantics to be incorrect -- you don't want to process one side of the join if the other side has not "caught up" in time! In addition, the processor must distinguish between “there are no locally buffered events” and “there are no events available to poll from the broker”. Needless to say, getting this right requires significant attention to the details.
After determining that a processor is ready to run, it will return events in timestamp order from each of the input partitions to ensure deterministic processing when there are multiple input topics (which is the case for joins).
Points to consider if you were to build your own stream processor:
- Make sure that you can process event streams deterministically, even in the case of out-of-order and late-arriving events, and both when replaying historical data and when processing live data.
- Make sure that your scheduler does not starve any processors, but don’t optimize too much for fairness — it makes sense to skip processors that are not ready to process and revisit them later.
How can I access data that’s on other machines?
Consequences of getting it wrong: in the worst case, data is missing or incorrectly processed — otherwise, there’s cost and performance overheads.
In a distributed system, data is partitioned across multiple instances. Some processing operations (such as joins and aggregations) require access to multiple datum that may not be available on the local machine that’s executing the processing step.
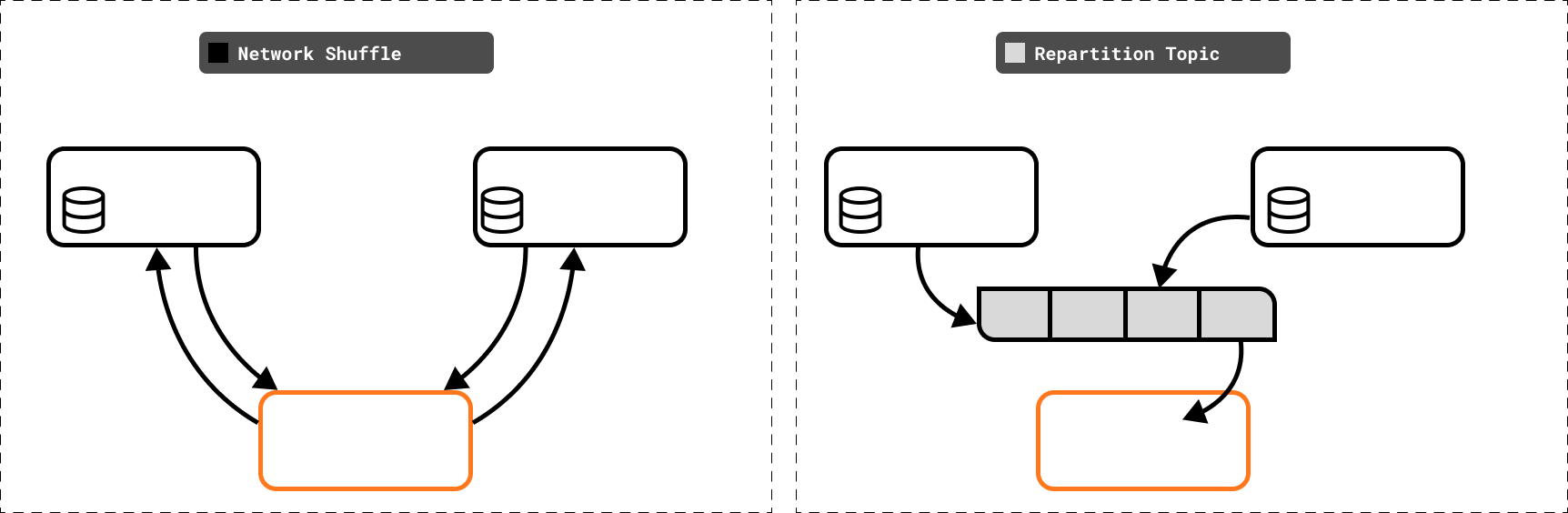
A stream processor has two options for working around this: (1) issue an RPC every time data is needed from another node or (2) shuffle the data so that requisite data is co-partitioned (present on the local instance). Kafka streams takes the second approach, which generally performs much better at high throughput, but implementing it correctly is challenging.
Kafka Streams, yet again, relies on Kafka to handle this problem for it by creating and managing internal “repartition” topics that change the key of underlying data to ensure that the aggregation or join key is also the partition key. This handles backpressure, routing and transactionality at the cost of managing an additional topic.
When should I commit the result of processing?
Consequences of getting this wrong: reprocessing data incorrectly or overwhelming downstream processors.
Committing data touches on more than just correctness (F3) — how and when you commit matters! There are considerations for transactional processing (see the previously mentioned post on this subject) and considerations around caching and incremental updates. When processing with exactly-once semantics, downstream processors won’t see updates until the commit interval elapses. When processing with at-least-once semantics, the commit interval interplays with the cache settings to determine how frequently incremental updates are sent to downstream processors.
There are also some non-standard reasons why you main want to trigger a commit. For one, there may have been no input records processed direcly but a punctuation may have produced a record out-of-band to the standard processing loop. In another, it is possible that records were processed from the input topic but resulted in no records being produced — this situation still requires a commit to move the input offsets forward.
Step 2: Make it Highly Available
Since Kafka Streams integrates only with Kafka as the message broker, it can leverage a significant portion of the work that was invested into the consumer group protocol, which ensures that all partitions are assigned and handles offset management so that a new instance can pick up where an old one left off.
The main mechanism for high availability (N2) in Kafka Streams is rebalancing, the ability to move partitions from one instance to another. This mechanism is fraught with tension between two conflicting goals:
Goal 1: Minimize partition processing downtime by detecting failures promptly and triggering rebalances.
Goal 2: Minimize disruption by avoiding unnecessary partition movement.
These goals influence the design for a stream processing system, and Kafka Streams has had nearly a decade to figure this out (see our full history on the evolution of rebalancing). If you were to design your own, you would need to answer the following questions:
When should I trigger a rebalance?
Consequences of getting it wrong: you’ll either have frequent rebalancing, which may cause reliability issues, or you won’t detect failed instances sufficiently soon to maintain SLA.
Kafka Streams simply leverages the Kafka Consumer Group protocol for identifying whether the system is healthy. If the protocol determines that the node is either down or not functioning as intended, it will indicate that partitions should be redistributed across the available instances (this is called a rebalance).
While this primitive encapsulates one of the most challenging distributed system problems, applications still need to tune the configurations for “what is considered down/not functioning” in order to balance the strain of unnecessary rebalances with the responsiveness to unhealthy instances.
There are a few key properties you’ll need to tune to get this working well (mostly session.timeout.ms and max.poll.interval). Kafka Streams automatically does its best to respect the poll interval by tracking time elapsed since the last poll and pausing/resuming partitions accordingly, and with Responsive you’ll get observability to help you tune these parameters intelligently.
How should partitions be assigned?
Consequences of getting it wrong: potentially “hot” instances in the case of an imbalanced assignment or extra computation for assignments that shuffle partitions around.
Kafka Streams uses a sophisticated strategy to assign partitions to instances in a way that ensures liveliness while minimizing data movement and maintaining a balanced load distribution. The ideal approach is to assign partitions based on their previous ownership to avoid disrupting ongoing processing and unnecessary state restoration (Kafka Streams calls this “sticky” assignment), ensuring that instances which previously processed a partition are reassigned to it if they are still available.
In the works (see KIP-924) is the ability to consider the processing load and capacity of each instance in addition to the previous allocation, distributing partitions in a way that avoids hot spots and ensures an even workload distribution across the cluster.
How can I minimize the disruption of a rebalance?
Consequences of getting it wrong: some or all partitions will pause processing during a rebalance.
Answering when and how a rebalance should happen is the starting point — the mechanics of the rebalance mechanism matter as well. Kafka Streams reduces the impact of rebalancing on the system's overall stability and performance through a few mechanisms:
- Cooperative rebalancing (see this post written by our founding engineer Sophie for the full details on that)
- Warmup replicas ensure that (see this KIP for an understanding of how that works).
- And more! There’s too much to cover in this blog post, such as cross-version upgrades and probing rebalances — perhaps we’ll follow this up someday with even more details into the nuances of rebalancing.
Step 3: Optimize
After building the foundations and ensuring you stay afloat, the next step is to figure out how to paddle faster and more efficiently.
Can my topology be optimized?
Building a topology (as discussed in the core runtime section) is the first step, but ensuring that it doesn’t cost more than necessary to execute is just as important for production applications. Kafka Streams can reduce unnecessary data shuffling and reuse state stores in some niche scenarios. To accomplish this, Kafka Streams is designed akin to a database execution engine: the topology is first built using a logical plan which is then translated into the optimized physical plan.
Identifying the best place to include a data shuffle is as much an art as a science. To read more about how Kafka Streams accomplishes this, see this blog.
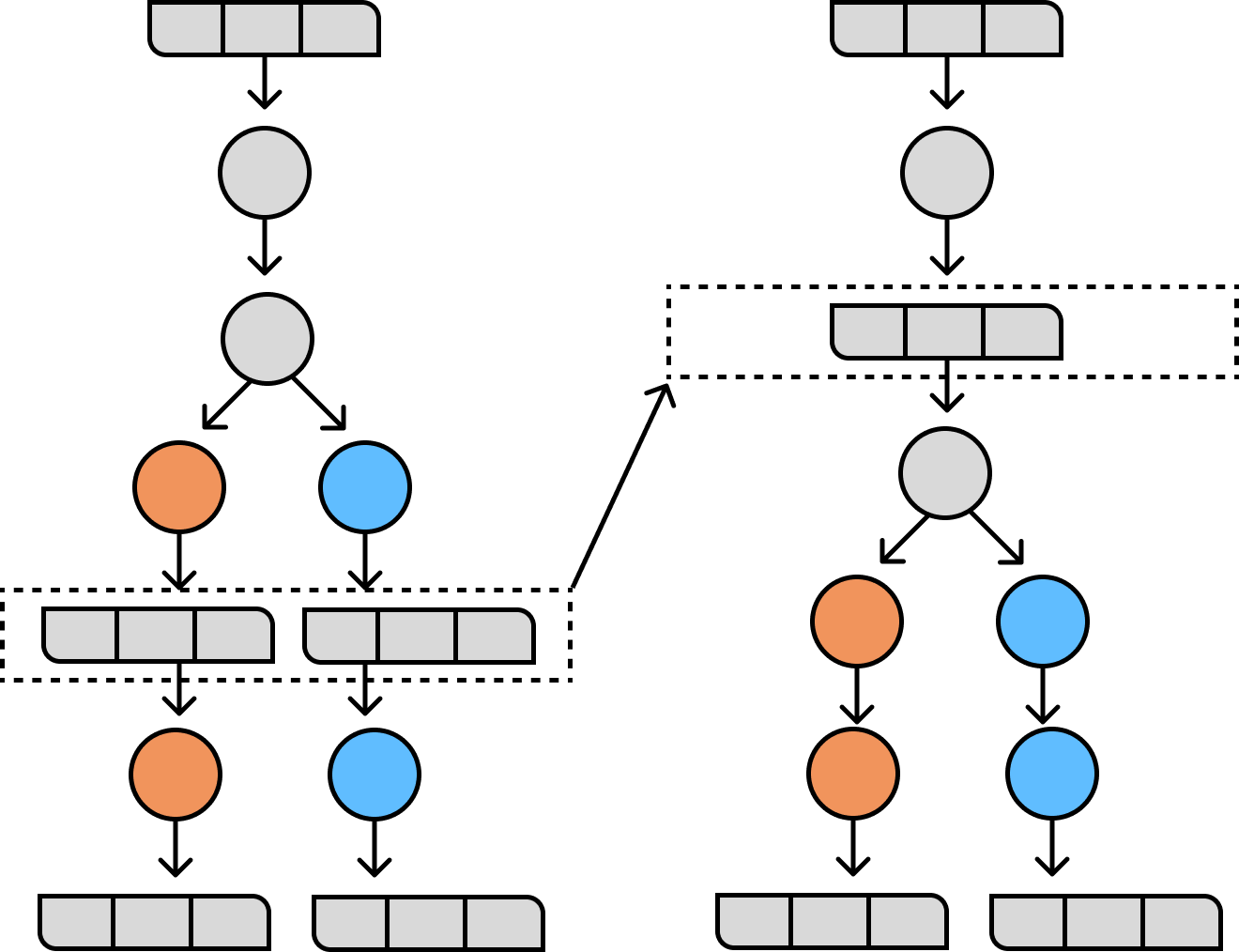
How can my processor effectively utilize multi-threading?
Kafka Streams splits units of work into “Stream Tasks” and assigns these tasks across the available “Stream Threads” on the instance. Since each task is independent, threads can utilize their underlying CPU efficiently by polling data for multiple tasks and processing only the tasks that have data available to process.
Should I consider buffering?
Stream processing has a significantly different workload pattern from traditional applications — the notable difference is that there is only a single active writer for any partition of data at any given time (excluding zombies, which is a topic deferred for another time!). This means that the result of computation can be buffered locally, and there’s no risk of another writer attempting to access the same data at the same time.
Leveraging this can reduce the amount of data that is unnecessarily sent to future steps in the topology. Take the example of a word-count aggregation: instead of sending an update downstream every time a word is processed you can send updates once every thousand words. Given the Zipf distribution of words in most natural bodies of text, words like “the” and “a” would likely account for a significant portion of the incoming events. With buffering, Kafka Streams can reduce the incremental update rate for those words significantly.
Step 4: Complete the Supporting Cast
So you’ve paddled this far along the pond and your stream processor is almost ready to go! Just as you exit the pond, however, you notice that you’ve reached a lake — your paddling has only just begun.
To take your technology to production, you need to complete the supporting cast. Kafka Streams comes out of the box with all of the following functionality, each of which is critical in its own right for effective usage in mission-critical infrastructure:
How do I test my applications?
Event-driven applications can be difficult to reason about and therefore difficult to test end to end. You want to be able to easily specify the correct inputs and outputs to the application without having to deploy real broker instances, which would make unit testing cumbersome (and likely to be unreliable on CI machines). The alternative is to mock/fake the kafka clients, which is not only requires significant investment of implementing a large API surface area but is also tricky to do correctly.
Kafka Streams solves this with its simple and deterministic testing harness for testing applications. The TopologyTestDriver was introduced in KIP-470 and is one of the most powerful testing harnesses in open source. Since creating the driver is identical to instantiating a KafkaStreams instance, all of your production code can be reused in your integration tests. All you need to do is define the events that are piped into the input topic and you can run tests quickly, without the need for a Kafka Cluster at all. You can see some full examples here.
How do I communicate what my application does?
Kafka Streams has a built in topology description tool that will output a text representation of the computation’s plan. This type of tooling is critical for debugging and documenting your Kafka Streams application.
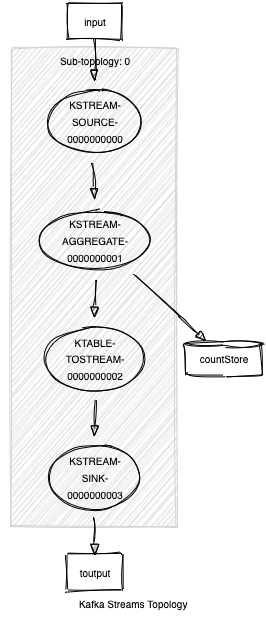
As an example, see the topology below that computes a simple count of its input and then converts that count table to a stream:
Topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000 (topics: [input])
--> KSTREAM-AGGREGATE-0000000001
Processor: KSTREAM-AGGREGATE-0000000001 (stores: [countStore])
--> KTABLE-TOSTREAM-0000000002
<-- KSTREAM-SOURCE-0000000000
Processor: KTABLE-TOSTREAM-0000000002 (stores: [])
--> KSTREAM-SINK-0000000003
<-- KSTREAM-AGGREGATE-0000000001
Sink: KSTREAM-SINK-0000000003 (topic: output)
<-- KTABLE-TOSTREAM-0000000002
This computation can be fed into an excellent open source visualizer and displayed in an easy to understand fashion:
How can I inspect the state in my application?
Another critical aspect of production grade software is the ability to inspect the state of your system to understand why an occurrence happened the way it did. Kafka Streams natively allows you to inspect the state of any instance using the interactive query capabilities.
How can I monitor my application and on what should I alert on?
Knowing what to monitor, what to alert on and what to look at to debug specific symptoms is something that can only be developed over many years of production experience with a system (even if you built the system yourself). Luckily, Kafka Streams has been central to mission-critical applications across hundreds of companies — which means every metric that’s important is already emitted as a JMX MBean, and there are many guides (such as our blog post and this excellent OSS dashboard) answering exactly which metrics to use for which purpose. With Kafka Streams you can avoid the awkward postmortem question “why did it take 2 days to notice the problem?”
When all else fails, where can I go for help?
Community is more than a fuzzy feeling. Having access to thousands of historical discussions, tickets, stack overflow posts and slack message threads makes it extremely likely that whatever problem you’re facing has been faced before — and if it hasn’t, the experts are engaged and ready to chime in at the drop of a hat. Most communities never hit the heights reached by Kafka Streams:
- The
apache-kafka-streamstag on Stack Overflow has over 4K questions - The ASF Jira has over 2K tickets that are actively labeled with
streamsas the component - The Confluent Slack Channel has over 40K members and hundreds of monthly messages (and incredibly quick time to first response)
Conclusion
Kafka Streams, much like the seemingly calm duck, can present a tranquil appearance while concealing a flurry of complex processes. These complex processes have had nearly a decade to stabilize and improve over time, and the end result is a foundational technology used ubiquitously for event driven applications.
Instead of shying away from the complexity introduced by innovation, we’ve embraced Kafka Streams as the foundation for Responsive — having built the mechanism that keeps the duck afloat, we’re not so eager to build it from scratch all over again!
1 June 27th, 2024 Update: The original post had links to some tickets that were only somewhat relevant. Thanks to Matthias J. Sax for suggesting these new, more relevant tickets!
Want more great Kafka Streams content? Subscribe to our blog!
Almog Gavra
Co-Founder