Async Processing: The Biggest Upgrade for Kafka Streams Since 0.11

Kafka Streams is the best framework for building mission-critical applications on Kafka event streams. A major reason is because it’s an embedded technology. So applications built with Kafka Streams integrate seamlessly with your development and operational processes.
Since Kafka Streams is embedded, developers often try to call other services and databases as part of handling events with Kafka Streams. For example, it’s natural to try to enrich your streams with data from a table in DynamoDB, or fire off an API call to another system to trigger some action based on the result of an aggregation.
Historically, you have have two choices to do this, both of which are suboptimal:
- If you only need to read information from the remote system, you can ingest it into a Kafka topic and then use the Kafka Streams join APIs to combine it with the data you're processing. This leads to complicated data pipelines and a wasteful duplication of data.
- Alternatively, you can make remote calls from your application's processors. However, remote calls can be slow, which severely limits your application's throughput.
That changes today. We are very excited to introduce the Responsive Async Processor, which extends Kafka Streams to make the latter approach practical - you can now introduce higher latency operations such as calls to remote systems in your Kafka Streams applications without sacrificing throughput.
And since the Async Processor is a regular Kafka Streams Processor, you can mix and match it with other Processors. So you can enrich an event from DynamoDB, join the enriched event with data in another Kafka topic, aggregate the joined event, and then fire off an alert if the aggregate value is above a specific threshold. All within a single Kafka Streams application which runs in your environment, and at scale!
Version 0.11 of Apache Kafka introduced exactly-once processing, which significantly expanded the types of applications you could build with Kafka Streams. We think the Async Processor is an equally big step forward because it enables you to interface with external systems via RPCs and Kafka events at scale, opening up a whole new set of use cases.
Read on to learn more about the traditional challenges when interfacing with remote systems from Kafka Streams, how the Async Processor addresses those challenges, how to use the Async Processor, how it works, and some of the results it has delivered in production already.
The problems with interfacing with external systems from Kafka Streams today
Before diving into the Async Processor, let’s dig a little deeper into why you may want to make remote calls, and the problems this creates for Kafka Streams.
If you’re intimately familiar with the problems posed by making remote calls from Kafka Streams, feel free to jump ahead for a look at how to use the processor and a brief glimpse into how it works internally.
Remote calls are a way to integrate your application with other systems. Let’s look at some use cases. We’ll illustrate these use cases using an example Kafka Streams application that handles “chat with support" requests for an online business by enriching and routing them. You can find the code for the example app here.
First, you might want to read data from an external system to incorporate it into your application. In our example, when a user initiates a request, the Kafka Streams app first needs to augment the event event with some metadata about the user that's stored in a DynamoDB database. In particular, we want to know what geographical location the user is in so they be routed to someone who is in the user’s time zone and speaks the user's language.
Next, you may want to call out to an external system to do some processing that doesn't make sense to do directly in your application. Continuing with our chat example, the application calls out to an AI inference engine (in this case, OpenAI's Moderate model) to detect if there is any language that violates the product's usage policies.
Finally, you might want to call out to an external system to write data computed by your application. Our chat app branches the KStream based on the results of the call to the Moderation model. For events that are flagged, it notifies a human by sending a Slack message so they can investigate further whenever it flags a policy-violating chat. Enriched events that were not flagged are routed back to Kafka for further processing.
The following topology diagram illustrates the example app’s topology. The red nodes are the ones that make external calls:
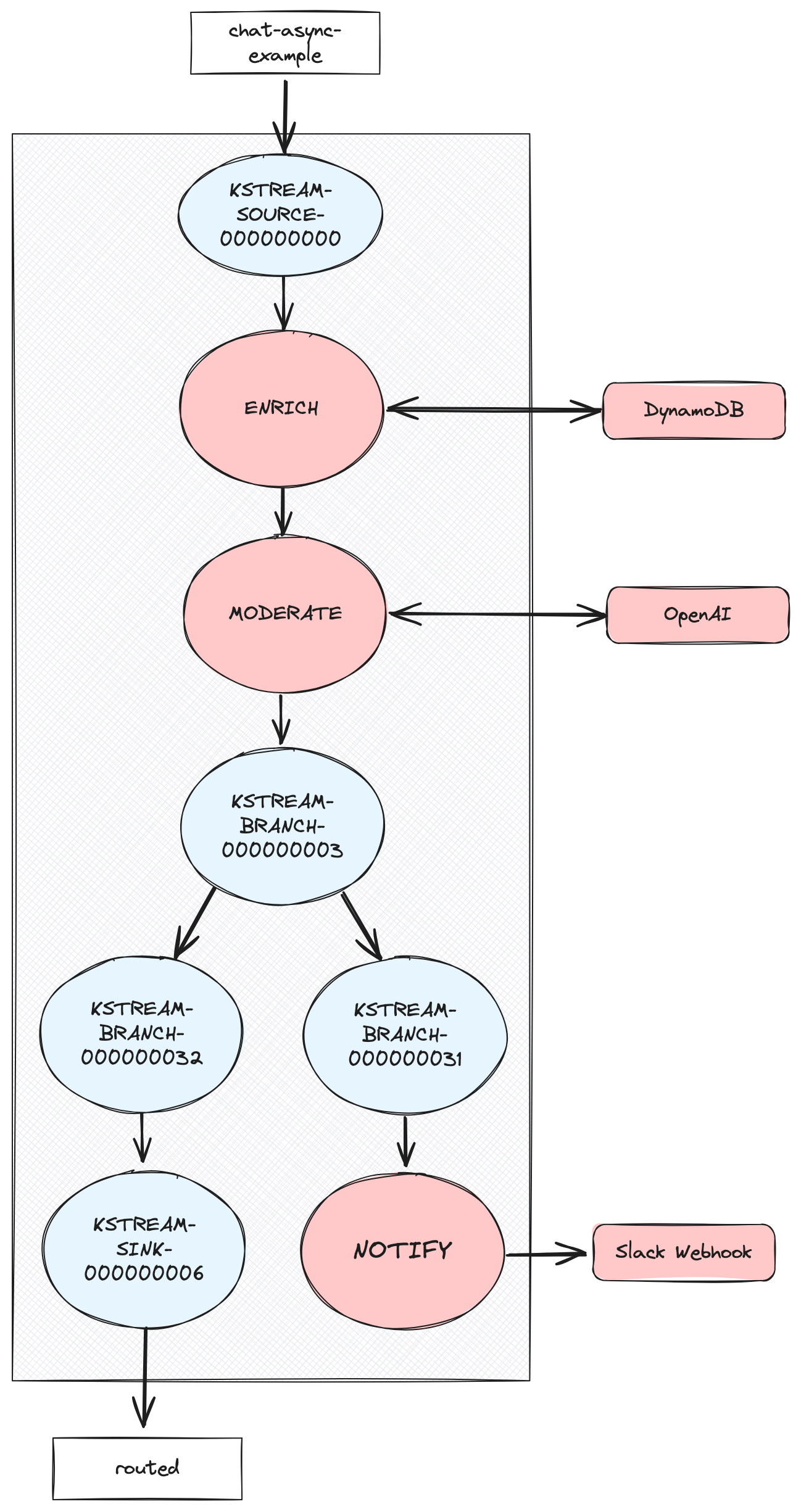
The options for interfacing with external systems today
Now lets dig into the approaches available to you to integrate with external systems using vanilla Kafka Streams and see why they may be problematic:
Go Through Kafka Topics
Let’s start with the recommended approach, which is to go through Kafka topics, rather than make external calls directly as we’ve done in the example:
- If you need to read data from an external system, then you can ingest that data into Kafka using a Connector, and then materialize it as a KStream/KTable.
- If you need to write data to, or trigger actions in an external system, then you can write it to Kafka from your application and then use a Connector to forward it on to the external system.
- If you need to handle the results of the api call from your application, like when handling the results of the inference engine in our chat app, then you can’t even use a Connector. You’ll have to write a Consumer/Producer application to make api calls to that system, and then write the results back to Kafka and consume them from your application.
This approach is expensive. You have to run connectors or Kafka client apps, and pay for the associated compute and data transfer. Then, you have to write the data coming from/going to the external system into Kafka. You have to pay for storage, and again for data transfers. Finally, you may need to materialize the state in your application, which again adds to the compute and storage cost. It's also fairly complex to set up (and operate!) the pipeline into or out of Kafka.
Make Remote Calls From Kafka Streams
Alternatively, you can make remote calls directly from your Kafka Streams application as we’ve done in the chat app. While this avoids the costs of going through Kafka for everything, it comes with some major drawbacks.
To understand the problems, let’s first review the streams task/thread model. Essentially, Kafka Streams breaks your application down into tasks, where each task represents consuming a Kafka partition and processing its records using your app’s topology (it’s more complex than this, but this is a good model for this discussion). Kafka Streams then assigns each task to a single thread responsible for executing the processing logic, called a StreamThread. Each StreamThread consumes records by polling the consumer, and then processes the polled records serially. As we’ll see below, serial execution of the processed records leads to major problems when making remote calls.
One issue users inevitably hit when making remote calls from their application is continuous rebalances from violating the poll timeout (max.poll.interval.ms). When a StreamThread returns from poll, it has to call poll again within the poll timeout. Otherwise, the application assumes that the thread has hung and removes it from the group via a rebalance. When you're making a call out to a remote service that can take 100s of milliseconds, it’s easy to hit this timeout because the StreamThread is blocked for the duration of the remote call.
The more serious issue is that blocking the whole StreamThread while processing each record can drastically reduce throughput. Further, as we’ll see below, Kafka Streams blocking behavior imposes a low ceiling on throughput - so you can’t even scale up to meet demand.
Because each StreamThread processes records serially, the thread’s throughput is inversely proportional to the average latency of processing a record. What’s more, this compounds as you add more remote calls to your application.
Let’s refer back to the topology diagram above. Remember, the red nodes are processors that make remote calls when processing each record. ENRICH calls out to DynamoDB to enrich the incoming chat requests with the user’s geography. MODERATE calls out to OpenAI to flag any requests with content that likely violates the usage policy. And finally, NOTIFY calls out to a Slack Webhook whenever it sees a flagged message.
Let’s see how each of these can affect throughput. DynamoDB calls should take ~10ms, if you factor in round-trip-latency with DynamoDB’s processing time. So if our app was just calling DynamoDB then each StreamThread could do at most 100 records per second. Let’s say calls to the moderate endpoint take ~90ms. With this latency factored in we’re down to a paltry 10 records/second, as illustrated in the following diagram depicting the position of the StreamThread (red box) on the source records (blue squares) over time:
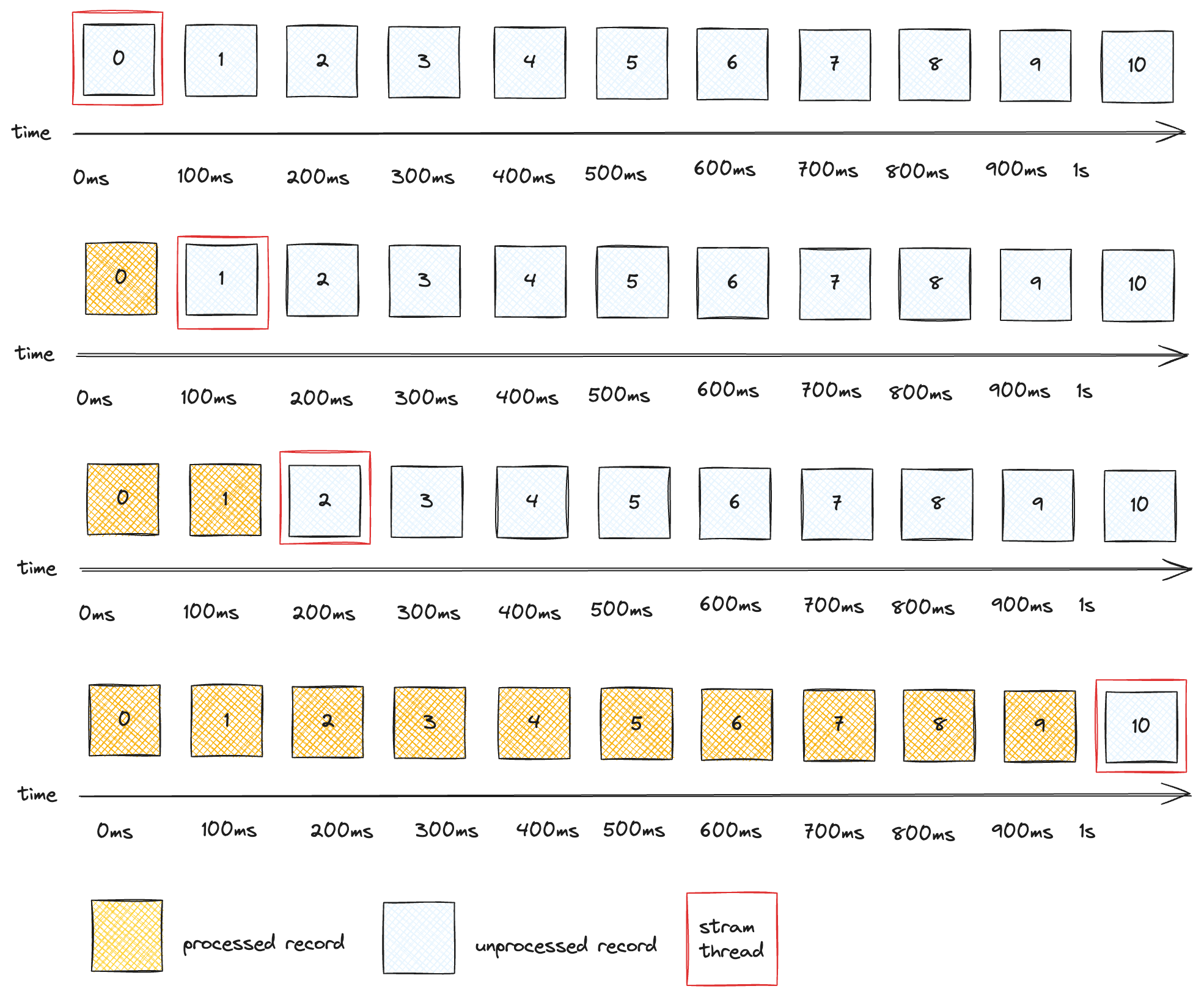
Finally, calls to a Slack WebHook also take ~100ms. But we can expect that messages won’t be flagged frequently, so it probably won’t impact throughput much, which is good because 10 records/second per StreamThread is pretty bad and will make it difficult, if not downright impossible, to meet most realistic workloads.
Workarounds
We’ve observed users try to work around this problem by adding StreamThreads. This can help, but it comes with two drawbacks:
More StreamThreads means more consumers. Each consumer is somewhat resource intensive, and having more consumers in a group increases the likelihood of spurious rebalances.
The bigger problem is that you can only add stream threads as long as there are enough tasks to be assigned to the StreamThreads you add. Remember, each task is assigned to exactly one StreamThread, and that StreamThread must process records from each of its assigned tasks serially. This means that there is a hard limit to the max throughput you can achieve with this approach.
Let’s go back to our example app. Let’s suppose that the input chat-async-example topic has 8 partitions. This means there are 8 tasks, and so the application can never go faster than 72 records/second! This is probably not going to cut it for most serious use cases, and more importantly imposes a hard ceiling on how much your application can ever scale.
We’ve seen some users work around this limitation by adding partitions. This can be expensive (especially if you’re using a managed Kafka provider), and besides, it’s very tricky to add partitions to a running application without sacrificing correctness. In fact, to our knowledge there is no clean path for doing this on a stateful application on vanilla Kafka Streams. As an aside, Responsive’s usage of remote state stores makes adding partitions practical - but that’s a topic for another post.
Remote calls done right: introducing the Async Processor for Kafka Streams
Responsive Async Processor unlocks the ability to run remote calls (or really, any long blocking operation) at scale directly from your Kafka Streams application by processing records with different keys within a single partition in parallel.
Furthermore, it does this while providing the exact same correctness guarantees as vanilla Kafka Streams.
As of this writing, it requires that your remote calls be executed from a Processor API (PAPI) processor. To use it, you simply wrap your PAPI ProcessorSupplier in a call to Responsive’s createAsyncProcessorSupplier . Here’s what it looks like for our example app:

You’ll also need to use Responsive’s Kafka Streams wrapper, which is a simple change to your call to create a new Kafka Streams instance, e.g:

AsyncProcessor works by running the processor’s process method on a separate worker thread pool that processes records in offset order for a key rather than the whole partition. This enables it to process multiple records per task/partition in parallel. This means that you can increase a StreamThread’s throughput by adding threads to the worker thread pool, even if the thread is only assigned a single task.
Let’s redo the analysis of our chat example, but this time using the Async Processor with a worker pool of 5 threads. With the async processor, assuming that all the records have distinct keys, the Streams Thread can now process 5 records at a time, as depicted in the diagram below:
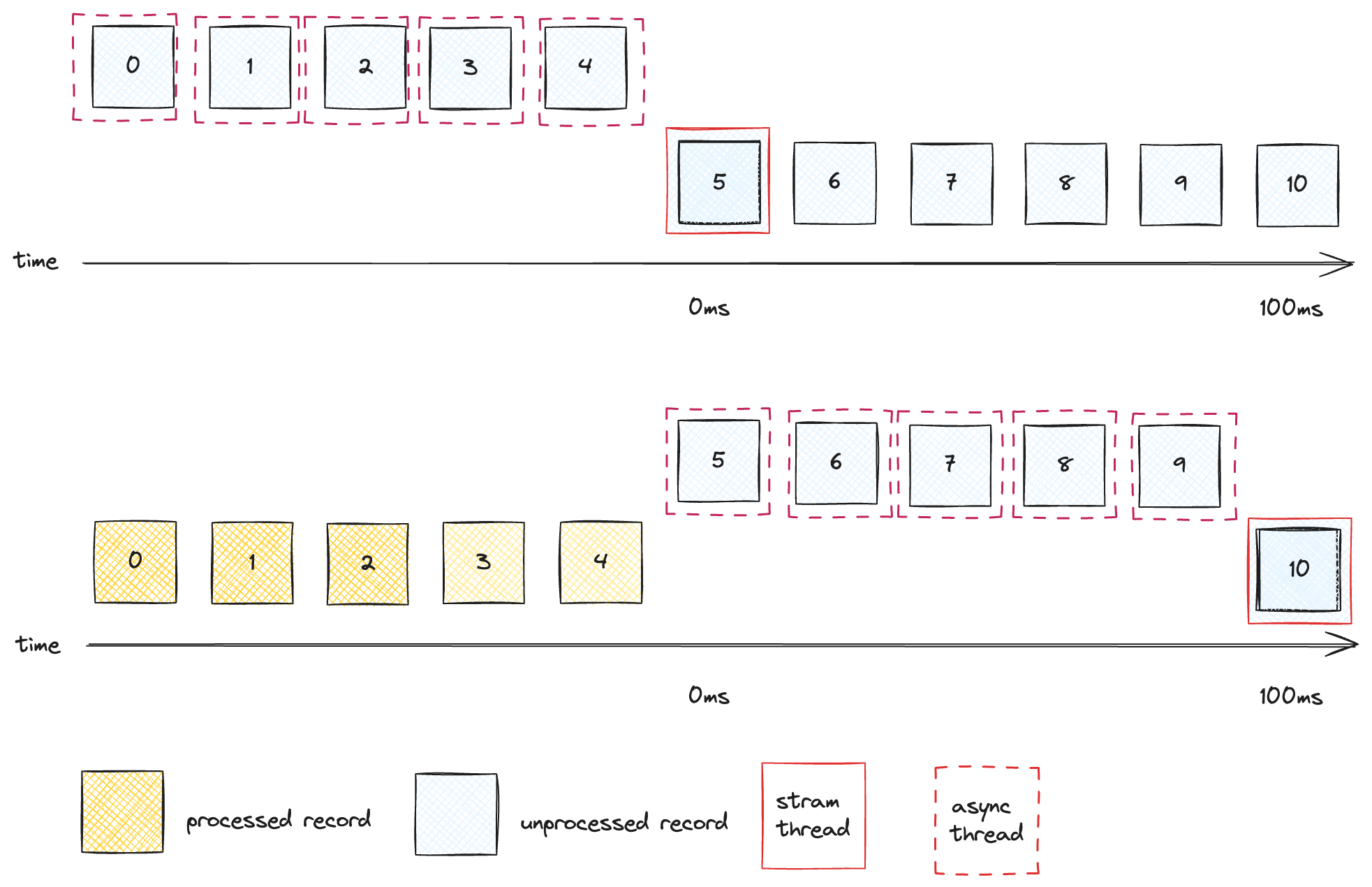
After 100ms, the Stream Thread will have finished processing the first 5 records, and moved on to the next bunch of 5 records. So what used to take us a whole second is now completed in just 200ms. Our app can now run 50 records/second per StreamThread, when before it could only do 10 records/second. What’s more, we can scale throughput up by adding worker pool threads rather than StreamThreads.
This is a time-tested strategy for increasing the processing rate of a queue of work (like a Kafka topic). Many other systems/protocols take a similar approach when the items in the queue have high latency. For example, HTTP/2 improves on HTTP/1 by letting clients multiplex multiple HTTP requests over a single TCP connection. So a browser can then quickly load a page requiring multiple resources over its limited pool of connections. Similarly, goroutines in Go, tasks in Rust, and virtual threads in Java 21 all allow you to multiplex multiple logical “threads” (which you could think of as a queue of instructions) over a limited set of OS threads.
In the case of Async Processor, we're using a secondary thread pool to multiplex high-latency processing of multiple records over a single Kafka Streams Thread assigned a Kafka topic partition. Note that we don't necessarily need to use a thread pool to do this - in the future we could instead run your processors on Virtual Threads instead to reduce the Async Processor's overhead. However the basic idea remains the same.
Looking Under the Hood
The astute reader familiar with Kafka Streams internals may be wondering how we can guarantee correct semantics when processing records outside of a Stream Thread. Indeed, this is the area that we spent the most time on when designing, implementing, and testing (more on this later) this feature.
Defining Correct Semantics
Let’s first specify what we mean by correct semantics. Put simply, we make sure we preserve the same Kafka Streams exactly-once (EOS) and at-least-once (ALOS) processing guarantees that you’re familiar with. But what does this mean for external API calls?
For most external API calls this means that the call will happen “at least once”. This works perfectly if you are executing reads against remote systems, or if your writes against remote systems are idempotent.
However, things get more complicated when the remote system is a state store for an EOS application. These need the full Kafka Streams EOS semantics. So we’ve taken care to build the Async Processor in such a way that when it's used with Responsive Managed Stores, you get the same exactly-once semantics that you would get with Kafka Streams' built-in (local) state store implementations.
We are going to write a followup post that dives into the details of how we achieve this, but in the meantime, here’s a sneak peek. We use Kafka as a transactional write ahead log, use Kafka transactions to write to the log atomically across multiple topics, and then use a compare-and-set operation to execute an atomic flush from the Kafka write ahead log to the remote state store. This also opens the door to exactly-once writes against any remote system that supports a compare-and-set primitive.
There were 3 major challenges to tackle to guarantee correct semantics with Async Processor:
Preserving Process/Commit Alignment
Each Kafka Streams thread runs a simple loop that polls the Kafka Consumer, executes the topology by calling process on the topology’s processors, and then commits the consumed offsets when all the records have been processed. It relies on the fact that when a given call to process for some record returns, the record is fully processed and its offset can be included in the commit.
This is not true with the async processor, which returns from process immediately after enqueuing the processor on an internal queue so that Kafka Streams can move on to the next record. To address this, Responsive Kafka Streams intercepts calls to commit the topology, and drains all the internal worker pool queues. This guarantees that all consumed records being included in the commit finish processing before the commit is actually sent to the brokers. This is how we ensure the same processing guarantees as a regular Kafka Streams application whether it uses ALOS or EOS.
Guaranteeing Key Order
Correct semantics require that records are processed in offset order for every key. To guarantee this, Async Processor maintains an internal queue per key that is passed to theprocess method. Records passed to process are enqueued on the queue for the record’s key, and blocked from processing until all previous records for the same key have been completed. When there is no record with a given key being actively processed by the worker threads, the processor consumes a record from the key’s queue and schedules it for processing.
Sandboxing The Processor
Each processor can make calls into Kafka Streams to drive further processing. In particular, processors can write to state stores and call ProcessorContext.forward to forward records to downstream nodes in the subtopology. Kafka Streams assumes that these calls are made from the Stream Thread and so it doesn’t synchronize concurrent access. This means that it’s not safe to call these methods from the async processor’s worker pool.
To solve this, Async Processor initializes each Processor with a sandbox instance of ProcessorContext. The sandbox instance mostly delegates to an actual ProcessorContext, with two exceptions:
- When it’s asked to load a State Store, it returns a sandboxed state store. The sandboxed state store delegates to the actual store for reads, but writes are written to an internal buffer.
- Then
forwardis called, the forwarded record is written to an internal buffer.
When process finishes executing, these internal buffers are passed back to the main Stream Thread, which drains them by calling the actual state store write methods and ProcessorContext.forward.
The Async Processor is Production Ready
The Async Processor has been thoroughly tested, and it’s production-ready. In fact it’s been used in production by Responsive’s customers for many months to process high volume transactional workloads.
Testing
To test Async Processor, we partnered with Antithesis to test that applications running the processor are stable and always produce correct results even in the presence of faults and unusual thread execution orderings.
Antithesis is an autonomous testing framework that executes your workload in a deterministic hypervisor and frequently injects faults like network outages and unusual thread interleavings to catch bugs - even those that happen very rarely. It doesn’t just inject faults - it injects them with intent by searching for faults that cause as yet unexercised code paths to be executed. So it actively looks for parts of the program that are rarely tested and therefore most likely to have undiscovered bugs. It also injects them with high frequency, so you can catch bugs within hours rather than after days or weeks of “real world” runtime. And because it’s deterministic it can always reproduce the bugs it catches.
We used Antithesis to shake out these bugs before our customers hit them.
For example, it discovered this bug, where the processor was causing a StreamThread to hang when the thread was fenced while it was in the middle of handling a completed async process call. It’s very difficult to catch this type of issue using the traditional approach of so-called “soak testing” by running a program for a long time in the hopes of catching non-deterministic bugs.
With Antithesis, we’re regularly able to catch these bugs the day they’re merged, well before our customers hit them. Catching them quickly also makes them much easier to debug. If you’re curious you can check out some of the other bugs we discovered here, and the workload we run here.
Production results
Our customers have been using the Async Processor for transactional workloads against managed Responsive state stores for the last several months. In that time, we have had zero issues with correctness or stability thanks to the extensive testing we did before the production rollout.
The following plots show a dramatic improvement in throughput per thread when using the Async Processor against a managed Responsive store.
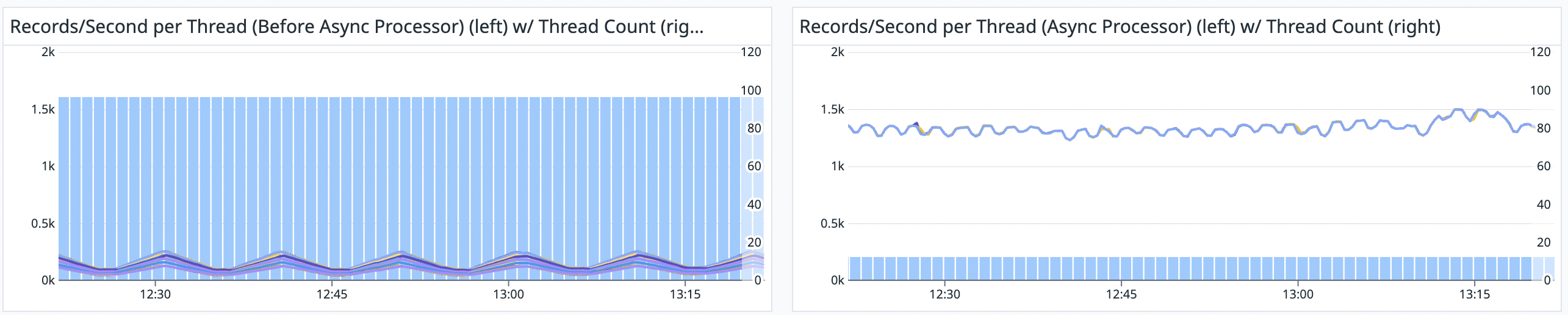
The plot on the left shows the throughput per thread (blue lines) and thread count (blue bars) before using the Async Processor. The customer had to run 96 threads to process their input topic. This is because each thread was bottlenecked waiting on Scylla reads, which took around 4 milliseconds to run. This means that each Stream Thread could process at most 250 records/second.
The plot on the right shows the same information after adopting Async Processor. With Async Processor, the same customer is able to run their workload with just 12 stream threads, each of which can process just under 1500 records/second. Further, as the append rate to the source topics increases, we can increase the application’s throughput by adding async worker threads, even if each stream thread were already down to a single task.
A small step for Kafka Streams, a giant leap for Stream Processing
We think the Async Processor is a major step forward for Kafka Streams and the Stream Processing landscape for a couple of reasons.
First, Kafka Streams is the only embedded stream processor that offers the full gamut of stateful stream processing APIs. Since it’s embedded, developers have naturally wanted to use it to interface with their existing services and databases. Until the Async Processor, this was impractical in many circumstances, thus closing the door to many compelling use cases.
Second, since we’ve implemented async processing as a Kafka Streams Processor, it integrates natively into your Kafka Streams applications and toolchains. The upshot of this design is that you benefit from all the current and future features of Kafka Streams, and of the Responsive control plane and Responsive managed state stores.
Combine these facts, and Kafka Streams and Responsive together now deliver stateful stream processing applications that embed without compromise into any environment, are backed by battle hardened remote databases as state stores, are powered by the most advanced autoscaler for streaming applications, and which can interface with other applications via both RPCs and Kafka. This is truly groundbreaking, and we are very excited about the use cases this will enable out in the world.
The Async Processor is available for every Responsive customer today. However, as we’ve mentioned before, we firmly believe that Kafka Streams’ most distinguishing feature is its ability to natively embed into your application and seamlessly integrate with your environment. The Async Processor adds a wholly new vector of integration with other applications. That’s why we believe this feature belongs in the core Kafka Streams product and are committed to contributing it back upstream to Apache Kafka.
If you’d like to try the Async Processor, it's available as part of the Responsive SDK for Kafka Streams. The SDK is a downloadable library you can add to your Kafka Streams application in 5 minutes. To learn more about the async procssor, check out the documentation. And if you have any feedback or questions, head over to our Discord.
Onward and upward!
Add Async processing to your Kafka Streams applications!